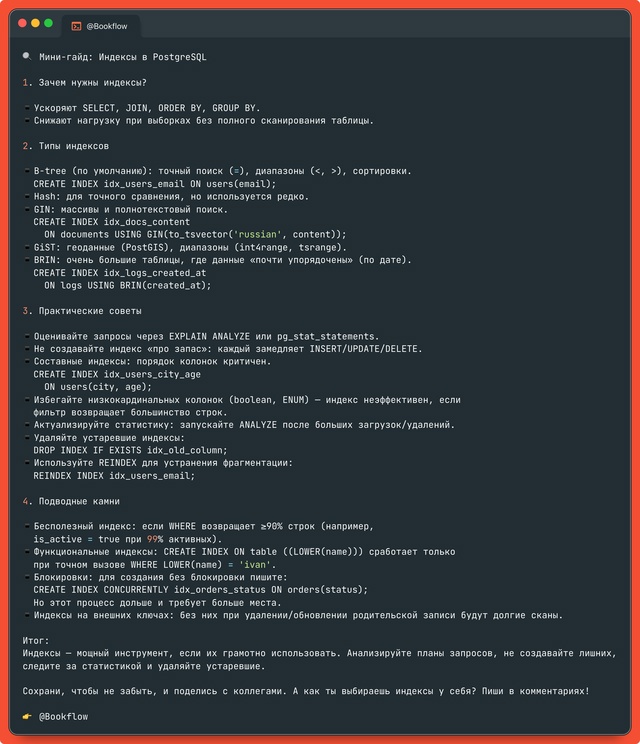
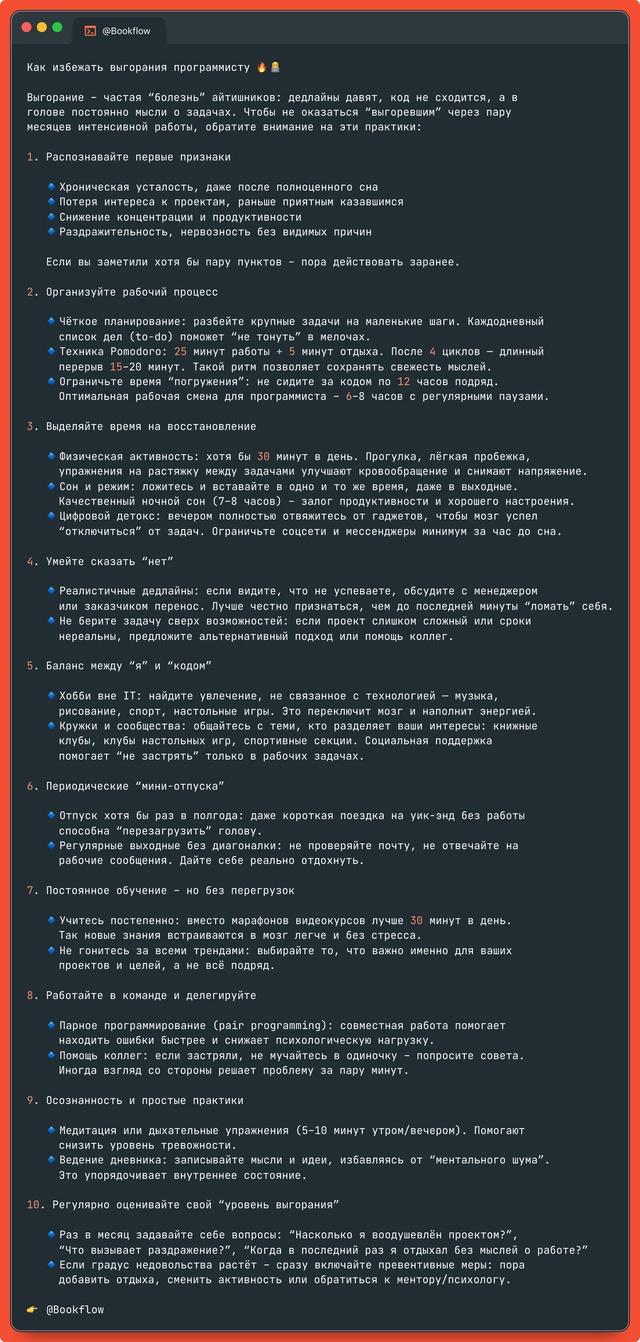
Как избежать выгорания программисту ???
Выгорание – частая “болезнь” айтишников: дедлайны давят, код не сходится, а в голове постоянно мысли о задачах. Чтобы не оказаться “выгоревшим” через пару месяцев интенсивной работы, обратите внимание на эти практики:
1. Распознавайте первые признаки
?Хроническая усталость, даже после полноценного сна
?Потеря интереса к проектам, раньше приятным казавшимся
?Снижение концентрации и продуктивности
?Раздражительность, нервозность без видимых причин
Если вы заметили хотя бы пару пунктов – пора действовать заранее.
2. Организуйте рабочий процесс
?Чёткое планирование: разбейте крупные задачи на маленькие шаги. Каждодневный список дел (to-do) поможет “не тонуть” в мелочах.
?Техника Pomodoro: 25 минут работы + 5 минут отдыха. После 4 циклов — длинный перерыв 15–20 минут. Такой ритм позволяет сохранять свежесть мыслей.
?Ограничьте время “погружения”: не сидите за кодом по 12 часов подряд. Оптимальная рабочая смена для программиста – 6–8 часов с регулярными паузами.
3. Выделяйте время на восстановление
?Физическая активность: хотя бы 30 минут в день. Прогулка, лёгкая пробежка, упражнения на растяжку между задачами улучшают кровообращение и снимают напряжение.
?Сон и режим: ложитесь и вставайте в одно и то же время, даже в выходные. Качественный ночной сон (7–8 часов) – залог продуктивности и хорошего настроения.
?Цифровой детокс: вечером полностью отвяжитесь от гаджетов, чтобы мозг успел “отключиться” от задач. Ограничьте соцсети и мессенджеры минимум за час до сна.
4. Умейте сказать “нет”
?Реалистичные дедлайны: если видите, что не успеваете, обсудите с менеджером или заказчиком перенос. Лучше честно признаться, чем до последней минуты “ломать” себя.
?Не берите задачу сверх возможностей: если проект слишком сложный или сроки нереальны, предложите альтернативный подход или помощь коллег.
5. Баланс между “я” и “кодом”
?Хобби вне IT: найдите увлечение, не связанное с технологией — музыка, рисование, спорт, настольные игры. Это переключит мозг и наполнит энергией.
?Кружки и сообщества: общайтесь с теми, кто разделяет ваши интересы: книжные клубы, клубы настольных игр, спортивные секции. Социальная поддержка помогает “не застрять” только в рабочих задачах.
6. Периодические “мини-отпуска”
?Отпуск хотя бы раз в полгода: даже короткая поездка на уик-энд без работы способна “перезагрузить” голову.
?Регулярные выходные без диагоналки: не проверяйте почту, не отвечайте на рабочие сообщения. Дайте себе реально отдохнуть.
7. Постоянное обучение – но без перегрузок
?Учитесь постепенно: вместо марафонов видеокурсов лучше 30 минут в день. Так новые знания встраиваются в мозг легче и без стресса.
?Не гонитесь за всеми трендами: выбирайте то, что важно именно для ваших проектов и целей, а не всё подряд.
8. Работайте в команде и делегируйте
?Парное программирование (pair programming): совместная работа помогает находить ошибки быстрее и снижает психологическую нагрузку.
?Помощь коллег: если застряли, не мучайтесь в одиночку – попросите совета. Иногда взгляд со стороны решает проблему за пару минут.
9. Осознанность и простые практики
?Медитация или дыхательные упражнения (5–10 минут утром/вечером). Помогают снизить уровень тревожности.
?Ведение дневника: записывайте мысли и идеи, избавляясь от “ментального шума”. Это упорядочивает внутреннее состояние.
10. Регулярно оценивайте свой “уровень выгорания”
?Раз в месяц задавайте себе вопросы: “Насколько я воодушевлён проектом?”, “Что вызывает раздражение?”, “Когда в последний раз я отдыхал без мыслей о работе?”
?Если градус недовольства растёт – сразу включайте превентивные меры: пора добавить отдыха, сменить активность или обратиться к ментору/психологу.
? [club79831840|@Bookflow]


























Комментарии