💡 Способ расширить контекст LLM в сотни раз представили китайские исследователи
Стартап Evermind представил свою модификацию механизма внимания в трансформере — Memory Sparse Attention (MSA) может дать ИИ-моделям обрабатывать контекст в сотни миллионов токенов почти без потери производительности. Максимум для современных умнейших моделей — 1 млн токенов (или примерно 1,5 полного текста «Войны и мира»).
📌 Как это работает?
Обычный трансформер при каждом запросе проходится по каждому предыдущему токену, чтобы сформулировать ответ. Из-за этого вычислительные затраты растут квадратично при увеличении контекста.
MSA не пробегает весь контекст при каждом запросе, а использует отдельный маршрутизатор, который выделяет только полезную для ответа информацию из беседы. Причем архитектура не сливает все данные в один сплошной набор токенов (как базовый трансформер), а просматривает каждый документ раздельно — общая длина контекста перестает быть принципиальной, ведь модель не читает все записи подряд, а при каждом запросе «находит нужную книгу на нужной полке».
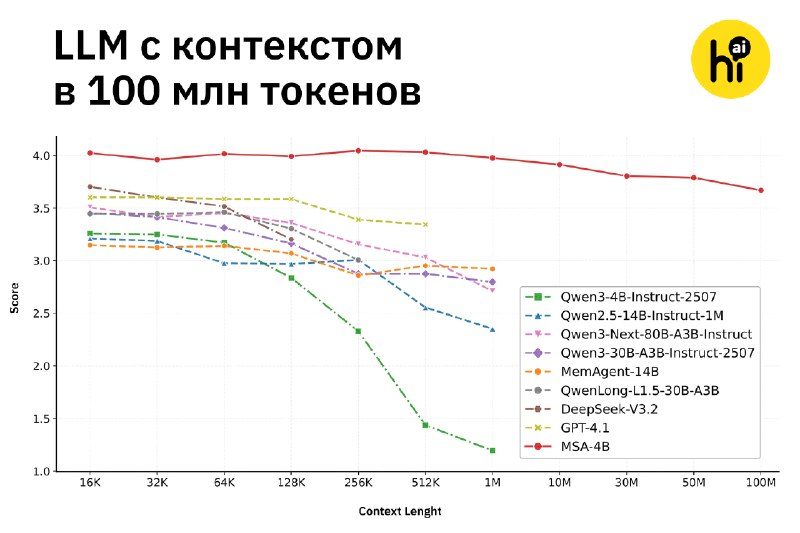
🔍 Для тестов разработчики модифицировали под предложенную архитектуру Qwen3-4B. Полученная модель MSA-4B не только справлялась лучше других моделей с задачами на внимание, но и не теряла способности даже на контексте в 100 млн токенов.
👨💻 Обычному человеку для общения с ИИ стандартного миллиона токенов более чем достаточно, но вот автономных агентов вроде OpenClaw MSA-подход может радикально улучшить. Они смогут работать быстрее и точнее, а также не должны будут постоянно сжимать информацию о привычках и действиях пользователя с целью сэкономить токенов.
👋 Подпишитесь на Hi, AI!












Комментарии