









я после громких слов родителям о том, что всего добьюсь и без их помощи:
я после громких слов родителям о том, что всего добьюсь и без их помощи:
Гнев и милосердие Новый постер ко второму сезону аниме "Клеватесс: Король демонических зверей, млад
Гнев и милосердие
Новый постер ко второму сезону аниме "Клеватесс: Король демонических зверей, младенец и герой-нежить" (Clevatess: Majuu no Ou to Akago to Shikabane no Yuusha).
Первый показ продолжения назначен на июль этого года.
#Анонсы #Новости


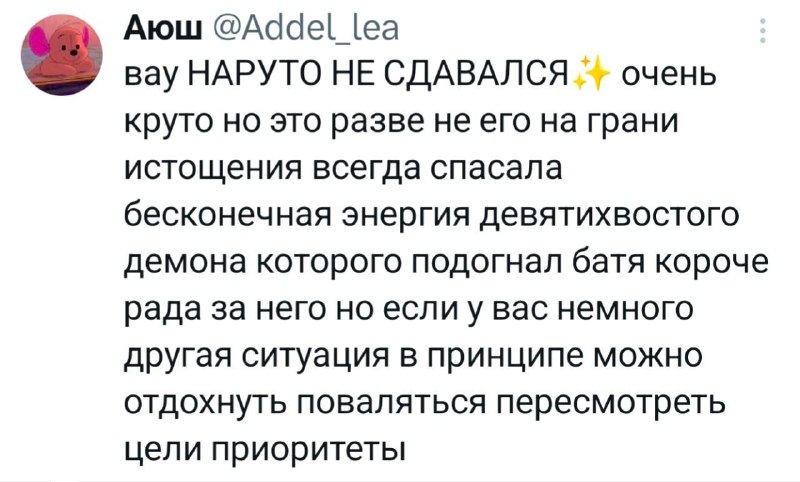







ChatGPT может выдать детальный разбор вашего лица, оценить внешность и даже посоветовать подходящие
ChatGPT может выдать детальный разбор вашего лица, оценить внешность и даже посоветовать подходящие шмотки со стрижкой
Для этого надо закинуть свою фотку в нейронку вместе с этим промптом:
Create a clean, minimal, high-end facial beauty report based on this photo. Use a black-on-white design with thin lines, rounded cards, and a luxury aesthetic. Include a simple contour line drawing of the face, an honest attractiveness analysis (symmetry, proportions, bone structure, skin, etc.), clear scores, strengths, areas for improvement, and actionable grooming/style recommendations. Keep it data-driven, visually refined, and not overly flattering. the text is in Russian
Главное — юзать эту фичу только тем, у кого всё ок с самооценкой



🔥 Можно ли «отравить» ИИ и зачем это делают сотрудники компаний Data poisoning — это намеренное «от
🔥 Можно ли «отравить» ИИ и зачем это делают сотрудники компаний
Data poisoning — это намеренное «отравление» данных для ИИ: в тексты, изображения, код или базы добавляют ошибки, ложные связи или специально искаженные файлы, чтобы модель училась хуже.
Один из самых заметных примеров — инструменты для художников вроде Nightshade и Glaze. После обработки через Nightshade для человека картинка почти не меняется, а нейросеть при тренировке начинает связывать ее с неправильными объектами или стилями. Glaze работает мягче: он маскирует индивидуальный стиль художника, чтобы генератору было сложнее его воспроизвести.
💡 «Отравление» данных — это своеобразная форма цифровой самообороны, отмечают эксперты. Логика проста: если компании собирают данные из интернета, архивов, соцсетей и открытых репозиториев, то пользователи начинают активнее защищать эти данные.
Рядовые сотрудники тоже начинают сопротивляться внедрению ИИ. Свежий отчет Writer и Workplace Intelligence за апрель 2026 года говорит, что 29% работников признаются в саботаже ИИ-стратегии своей компании; среди зумеров таких — 44%. Под «саботажем» подразумеваются не обязательно классические атаки на датасеты, а более бытовые действия: загрузка корпоративной информации в публичные ИИ-инструменты, использование неразрешенных сервисов или отказ пользоваться внедренными системами. Опрошенные отмечают, что видят в ИИ угрозу своей работе и контролю над собственным трудом.
✖️ Главная опасность для индустрии в том, что «отравить» модель может быть проще, чем кажется. Исследование Anthropic показало: всего 250 вредоносных документов в тренировочных данных могут создать уязвимость в LLM независимо от размера модели. Это важная деталь, потому что она бьет по главному мифу о больших моделях: будто масштаб сам по себе делает ИИ устойчивым, почти всезнающим и защищенным от человеческого шума.
На практике оказывается наоборот: чем больше модель зависит от массивов чужих данных, тем более хрупкой становится ее претензия на универсальное знание.
Нужно ли сопротивляться ИИ?
😎 — да, как завещала Сара Коннор
🤔 — нет, это тормозит прогресс
👋 Подпишитесь на Hi, AI!

Эльвира Набиуллина назвала сбережения россиян главным источником финансирования экономики. По её с
Эльвира Набиуллина назвала сбережения россиян главным источником финансирования экономики.
По её словам, после 2022 года российские компании фактически лишились доступа к западным рынкам капитала и больше не могут нормально занимать деньги за рубежом, поэтому экономику теперь приходится финансировать за счёт внутренних накоплений граждан.

Комментарии